
Data Science is a relatively new subject that needs to be delved into for clarity as it has various aspects and unanswered questions, we, at Edu Plus Now are here with a Beginner’s Guide to Data Science. The 1st part of the blog will cover topics like what is data science, what does a data scientist do, and what are the steps they follow while conducting a Data Science Project. The 2nd part will go up shortly, make sure you check it out too.
What is Data Science?
Ever wondered how online streaming platforms know which shows to recommend to you based on your ratings, the shows you previously watched, and your preferences? Ever wondered why the products line-up of ‘Frequently Bought Together’ or ‘Customers Also Bought’ when you add something to your cart on online shopping sites and applications? When you place an order on a food delivery application, how do they instantly curate the ‘You may also like’ line-up?
The world has entered the era of data and digits very swiftly and extensively in the past two decades. And with the steep rise in data acquisition grew the need for storage space and internet usage. Ten years ago, Artificial Intelligence was the ‘IT’ thing in the market. Ten years down the line, Data Science will undoubtedly be the ‘IT’ thing.
In simple words, Data Science is an amalgamation of various tools, algorithms, and machine learning principles to discover what the consumers want. Now some of us may wonder, ‘Haven’t statisticians done this for years?’. The answer is yes, they have. But the significant difference is that a Data Analyst usually explains what is going on by processing the history of the data. On the other hand, a Data Scientist not only conducts the exploratory analysis to scoop out insights from it but also uses various advanced machine learning algorithms to recognize the occurrence of any probable event in the future. A Data Scientist looks at the data from different sources including the ones often missed out by an average statistician. For better explanation and clarity, you can study the flowchart below –
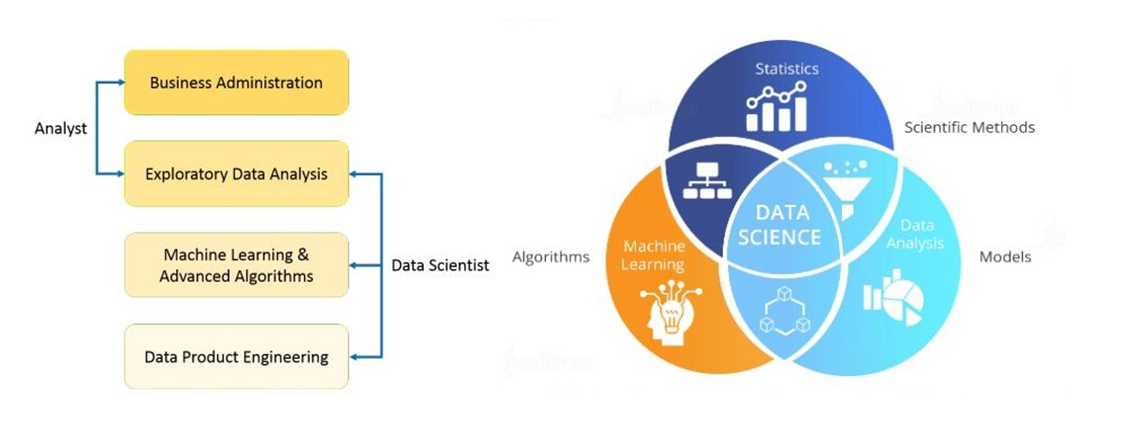
What does a Data Scientist do?
A Data Scientist cracks complex data problems with their brilliant expertise in some particular scientific disciplines where they work with different elements related to mathematics, statistics, computer science, and many more. They make a lot of use of the latest technologies in finding solutions and reaching conclusions that are crucial for an organization’s growth and development. Data Scientists present the data in a much more useful form as compared to the raw data available to them from structured as well as unstructured forms.
What are the steps they follow?
- As a Data Scientist, the first step in working a Data Science project is to understand the business problem first. Asking relevant questions during the client meetings is very vital as it helps you understand and define the objectives of the problem that need to be tackled.
- After understanding the business problem, a Data Scientist starts gathering data from multiple sources like web servers, logs, databases, APIs, and online repositories. Finding the appropriate and useful data takes both time and effort, and you can learn the processes and prerequisite techniques by taking up the course.
- After the data is gathered, comes the preparation of data. This step involves Data Cleaning; which is the most time-consuming process as it involves handling many complex scenarios and Data Transformation; where the data is modified based on defined mapping rules.
- In the data cleaning process, you may have to deal with many complications, viz a viz inconsistent data type, misspelled attributes, missing and duplicate values, and it goes on.
- In the data transformation process, understanding what one can do with the compiled data is very crucial, and for that, you can do exploratory data analysis.
- With the help of Explanatory Data Analysis, you can define and refine the selection of feature variables that will be used in moral development. Skipping this step may end up using the wrong variables that will result in the production of an inaccurate model. Thus, concluding in making this step the most important one amongst all.
- Data modeling is a core activity of any data science project. This step is where you repetitively apply type-force machine learning techniques like KNN, Decision tree, and Naive Bayes to the data to identify the moral that best fits the business requirement. You must train the models on the training data set and select the best performing model.
- Communicating with the clients and convincing the stakeholders about the business findings efficiently and effectively is rather necessary. She also uses different tools that help her create powerful reports and dashboards for the appeal that help the onlooker in deciding their next step.
- In the last step, Data Scientist deploys and maintains the selected model by testing it in a pre-production environment before deploying it in a production environment. After successfully disposing of it, they use the reports and dashboards to obtain real-time analytics.