
In the first part of the article, we read about what is Data Science, what does a Data Scientist do, and the steps that are followed in a Data Science Project. In this part, we will read about
Business Intelligence and how it is different from Data Science, the various tools needed to
conduct some steps in a Data Science project, and the components of a successful Data Science project.
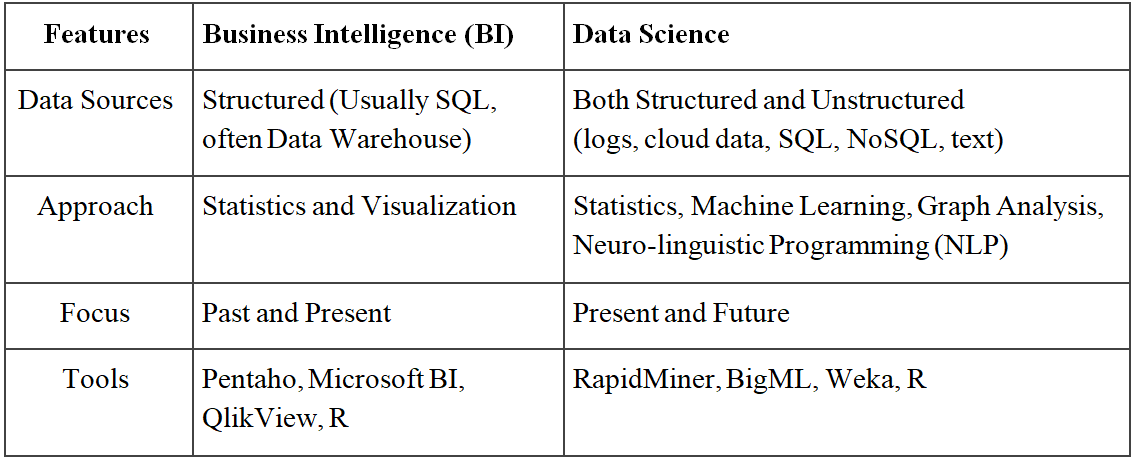
How does Data Science differ from Business Intelligence (BI)?
Business Intelligence is the tool that analyzes the previous data to find hindsight and insight to describe business trends. This tool enables you to take data from external as well as internal
sources, and prepare them, run queries on them, and create dashboards to answer all sorts of questions that arise while conducting the study. All in all, Business Intelligence can evaluate the impact of certain events forthwith.
Data Science, on the other hand, is a more progressive and modern approach. It is an exploratory way that focuses on analyzing the past or current data and the predicted future outcomes to make well-informed decisions. It answers the indeterminate questions as to “what” are the feasible events that will transpire and “how” will they occur.
Let’s compare both of them on the basis of some features and find out how they vary from each other –
 Components of Data Science
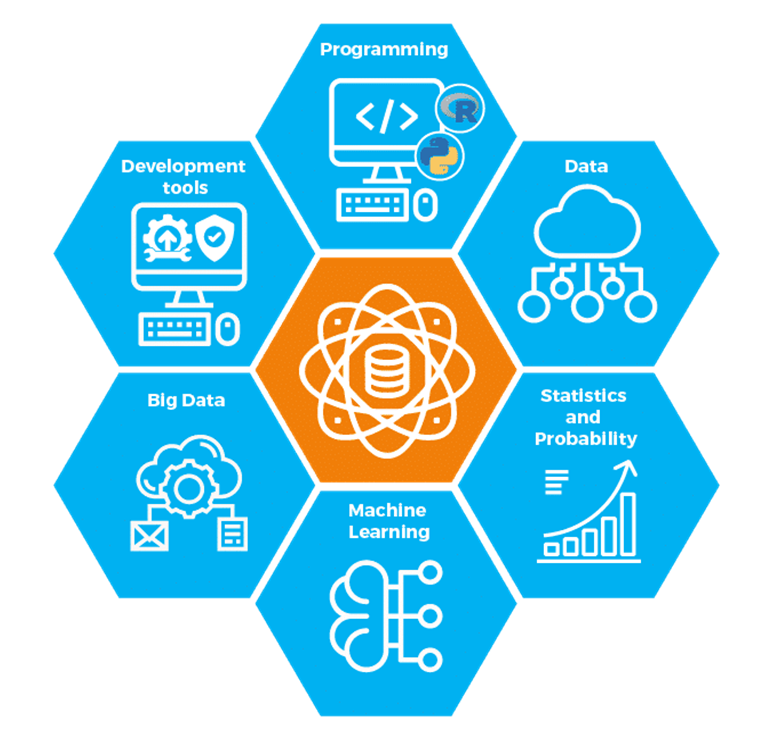
Components of Data Science
The various components of Data Science are –
- Data and its different types – The raw dataset is the foundation of Data Science and it can be in both forms of structured and unstructured data.
- Programming – Data management and analysis are done by computer programming and the most popular languages are Python and R.
- Statistics and Probability – Data is used to extract information out of it and it is imperative to use statistics and probability as they play a crucial role in Data Science. The mathematical foundation of Data Science is statistics and probability and the knowledge of statistics and probability should be impeccable to avoid misinterpreting data and reaching incorrect conclusions.
- Machine Learning – As a Data Scientist, Machine Learning algorithms such as regression and classification methods are used regularly. So, a Data Scientist needs to have the knowhows of Machine learning so that they can predict valuable insights from available data.
- Big Data – In the digital world, the application of Data Science can result in the extraction of different kinds of information from raw data. There are many tools used by Data Scientists to process big data.
Tools used for Model Planning.
There are various common tools for Model Planning are –

- SQL Analysis Services – SQL Analysis Services is used to perform in-database analytics. This planning tool uses common data mining functions and basic predictive models.
- R – R is another tool that has a complete set of modeling capabilities and provides a good environment for building interpretive models.
- SAS/ACCESS – This tool can be used to access data from Hadoop, which is open-source software that facilitates data from a network of many computers, and is used for creating visually appealing and effective model flow diagrams.
Of all these commonly used tools, R is the most used one owing to its high availability as it is open-source software.
Tools used for Model Building.
The different and most common tools used for building models are –

- SAS Enterprise Miner – SAS Enterprise Miner helps you analyze complex data, discover patterns, and build models so one can easily detect fraud, anticipate resource demands, and minimize customer attrition.
- WEKA – WEKA is open-source software that provides tools for data pre-processing, implementation of several Machine Learning algorithms, and visualization tools so that machine learning techniques can be developed and be applied to viable data mining problems.
- SPSS Modeler – SPSS Modeler provides predictive analytics that helps in uncovering data patterns, gain predictive accuracy, and improve decision making.
- MATLAB – MATLAB is a multi-paradigm numerical computing environment and a proprietary programming language which allows matrix manipulations, plotting of functions and data, implementation of algorithms, creation of user interfaces, and interfacing with programs written in different languages.
- Alpine Miner – Alpine Miner facilitates collaboration and the capturing of collective intelligence with libraries and self-documenting workflows and enables business users of an organization to institutionalize the predictive modeling process and become truly data-driven.
- Statistica – Statistica uses techniques of extraction in an attempt to aggregate or combine the predictors in some way to furnish the common information contained in them that is most useful for building the model.